概率论与数理统计
概率(Probability):描述事件发生的可能性的一个数值
概率和统计其实是互逆的,概率论是对数据产生的过程进行建模,然后研究某种模型所产生的数据有什么特性。而统计学正好相反,它需要通过已知的数据,来推导产生这些数据的模型是怎样的
随机事件
样本空间和随机事件
- 随机试验
- 可在相同条件下重复进行(可重复性)
- 全部结果是已知的(结果已知性)
- 事前无法预知结果(不可预测性)
- 随机事件
- 在随机试验中,对某些现象的陈述
- 必然事件Ω
- 不可能事件∅
- 基本事件:一次试验中必发生且最简单的事件
- 复合事件:若干基本事件组成
- 样本空间
- 样本点:试验的每一个可能结果
- 样本点全体称为样本空间
事件关系和运算
- 包含
- A发生必然导致B发生
- A ⊂ B
- 如果 A ⊂ B 且 B ⊂ A,则 A = B
- 和(并)事件
- A ∪ B
- 积(交)事件
- A ∩ B 或者 AB
- 互不相容(互斥)
- 事件A,B不可能在一次试验同时发生
- 对立事件(逆事件)
- B = {A不发生}
- B = A
- 差事件
- A-B 或 AB
运算律

事件的概率
事件A发生的可能性大小为P(A) 称为A的概率
A出现的频率 = (A出现的次数/实验总次数)
古典概型
- 实验结果为有限个
- 各个结果发生的可能性相等
P(A) = (A出现的次数/实验总次数)
几何概型
允许实验结果为无限个
公理化定义
- 非负性 ,0 ≤ P(A) ≤ 1
- 规范性 P(Ω) = 1
- 完全可加性 n个事件并集概率 = n个事件加起来的概率
性质:
- P(∅) = 0 不可能事件概率为0
- n个事件并集概率 = n个事件加起来的概率
- P(A)+P(A)
- P(B-A)=P(B)-P(AB)
- P(A∪B)=P(A)+P(B)-P(AB)
条件概率与事件的独立性
条件概率
已知事件B发生的条件下,事件A发生的可能性的客观度量称为条件概率,记为P(A|B)。也就是某个事件受其他事件影响之后出现的概率
P(A|B) = P(AB) / P(B)
- 乘法定理
P (AB) = P(A)P(B|A) P (AB) = P(B)P(A|B)
全概率公式
用于多个原因导致一个结果发生
有互不相容事件B1 B2 B3 BN B1...BN 概率和为1 A为Ω中的一个事件 则 A = P(AB1) + P(AB2)...
贝叶斯公式
结果为x的事件,求y导致其发生的概率
P(x|y) = P(y|x)XP(x)/P(y)
贝叶斯原理
- 先验概率:通过抽样得到的事情发生的概率
- 后验概率:发生结果之后,推测原因的概率
- 条件概率
- 似然函数
贝叶斯原理就是求解后验概率
朴素贝叶斯
基于一个简单假设建立的一种贝叶斯方法,并假定数据对象的不同属性对其归类影响时是相互独立的
结果为x的事件,求y,z导致其发生的概率
P(x|y,z) = P(x|y) X P(x|z)
在 A1、A2、A3 离散属性下,$C_j$ 的概率:
$$ P(C_j|A_1A_2A_3) = \frac{P(A_1A_2A_3|C_j)P(C_j)}{P(A_1A_2A_3)} $$
如果要处理连续值,则通过样本计算出均值和方差,也就是得到正态分布的密度函数转成离散值
在机器学习中,通过事先对对象提取各个特征,计算可能性,再对未知对象时,通过各个特征的分值,就可以计算对象属于什么类的概率
VS其他算法:
- 和 KNN 最近邻相比,朴素贝叶斯需要更多的时间进行模型的训练,但是它在对新的数据进行分类预测的时候,通常效果更好、用时更短
- 和决策树相比,朴素贝叶斯并不能提供一套易于人类理解的规则,可以提供决策树通常无法支持的模糊分类
- 和 SVM 支持向量机相比,朴素贝叶斯无法直接支持连续值的输入
朴素贝叶斯模型中的连续乘积会导致过小的值,甚至计算机都无法处理。为了避免这种情况,我们可以使用 log 的数学变换,将小数转换为绝对值大于 1 的负数
文本分类:
准备好各个词属于哪个分类的概率 -> 文本分词 -> 使用朴素贝叶斯计算分出的词属于哪个分类可能性最大
事件的独立性
若P(A|B) = P(A) 或 P(B|A)=P(B) 或 P(AB)=P(A)P(B)
则事件A与B互相独立
马尔可夫假设
- 任何一个词 wi 出现的概率只和它前面的 1 个或若干个词有关
链式法则:P(x1,x2,x3,...,xn) = P(x1) X P (x2 | x1) X P(x3 | x1, x2) X P(xn | x1,x2,...,xn-1)
二元文法模型:某个单词出现的概率只和它前面的 1 个单词有关
P(wn | w1,w2,...,wn-1) ≈ P(wn | wn-1)
语言模型可以用来:
- 信息检索:给定一个查询,哪篇文档是更相关的
- 分词:可以估算出基于词典分割的方式,哪种分割最为合理
马尔可夫模型
状态到状态之间是有关联的。前一个状态有一定的概率可以转移到到下一个状态。如果多个状态之间的随机转移满足马尔科夫假设,那么这类随机过程就是一个马尔科夫随机过程,刻画这类随机过程的统计模型,就是马尔科夫模型
隐含马尔可夫模型:像在语音识别中,同样的发音可以被识别为不同的文字,那么使用隐含模型,就可以在所有可能的识别结果中,选择可能性最高的一个
信息熵
刻画给定集合的纯净度大小的一个指标,纯净度的大小与元素种类多样性成反比
信息增益:对元素种类划分后,系统整体熵的下降
一种决策树算法就是每次计算问题的信息熵,挑选信息增益最高的问题,也就是区分度最高的问题
特征选择
如果一个特征,经常只在某个或少数几个分类中出现,而很少在其他分类中出现,那么说明这个特征具有较强的区分力,这个时候,对于一个特征,我们可以看看包含这个特征的数据,是不是只属于少数几个类,就可以使用信息熵来计算区分度:
$$ -\sum_{j=1}^nP{\left(c_j\mid Df_i\right)}\times\log_2P{\left(c_j\mid Df_i\right)} $$
另外一种方式是卡方检验来检验两个变量是否相互独立:
如果两者独立,证明特征和分类没有明显的相关性,特征对于分类来说没有提供足够的信息量。反之,如果两者有较强的相关性,那么特征对于分类来说就是有信息量的,是个好的特征。
特征变化
- 归一化:是获取原始数据的最大值和最小值,然后把原始值线性变换到[0,1]之间,这种方法有个不足最大值与最小值非常容易受噪音数据的影响
x' = (x - min) / (max - min)
- 标准化:该方法假设数据呈现标准正态分布,z 分数标准化是利用标准正态分布的特点,计算一个给定分数距离平均数有多少个标准差,不容易受到噪音影响
x' = (x - 均值) / 标准差
随机变量及其分布
随机变量:对于Ω上的每一样本点w,都有一个实数与之对应,则称X(w)的X为随机变量,用来描述事件所有可能出现的状态
分布函数F(x)=P(X<=x>)
概率分布描述的其实就是随机变量的概率规律
离散型随机变量
有一类随机变量可能的取值是有限个或可列无穷个,称之为离散型随机变量
各个可能的取值组合起来称之为随机变量X的分布律
- 常用离散型分布
- 0-1分布、伯努利分布:单个随机变量的分布,而且这个变量的取值只有两个,0 或 1
- 二项分布:描述了一个具有 k 个不同状态的单个随机变量
- 几何分布
- 泊松分布
连续型随机变量
一些随机变量的可能取值可充满一个区间,称之为连续型随机变量
常用连续型分布
- 均匀分布
- 指数分布
- 正态分布、高斯分布:,越靠近中心点μ,出现的概率越高,而随着渐渐远离μ,出现的概率先是加速下降,然后减速下降,直到趋近于 0
期望值
也叫数学期望,是每次随机结果的出现概率乘以其结果的总和
二维随机变量及其分布
对于Ω上的每一样本点w,有两个实数XY与之对应,则(X,Y)为二维随机变量
- 联合分布函数
二维离散型随机变量
二维连续型随机变量
统计意义
显著性差异:研究多组数据之间的差异是由于不同的数据分布导致的呢,还是由于采样的误差导致的
- 虚无假设:H0,事先对随机变量的参数或总体分布作出一个假设,然后利用样本信息来判断这个假设是否合理
- 队里假设:H1,如果证明虚无假设不成立,那么就可以推出对立假设成立
P 值:当 H0 假设为真时,样本出现的概率
方差分析,也叫 F 检验。这种方法可以检验两组或者多组样本的均值是否具备显著性差异
过拟合与欠拟合
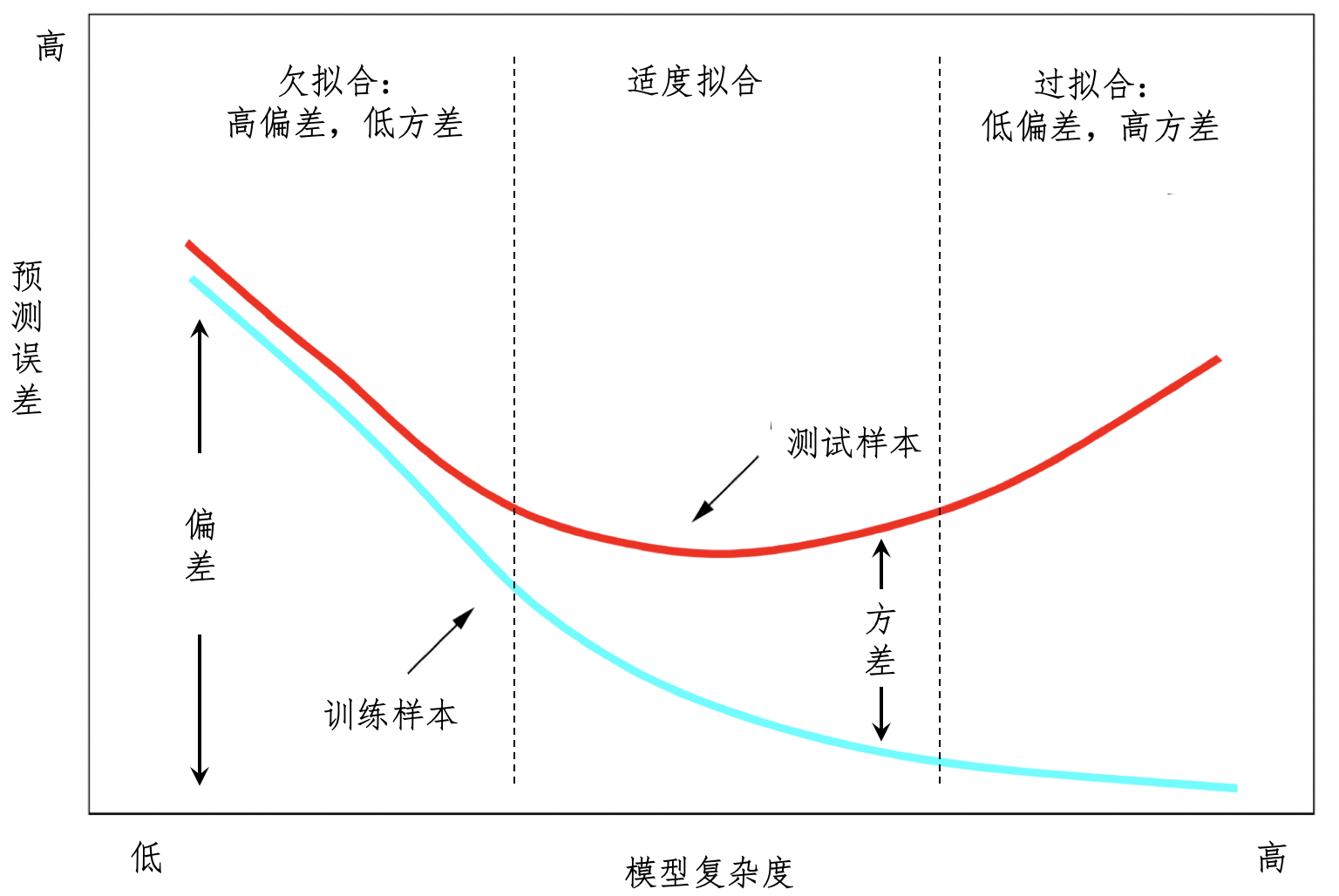
- 欠拟合问题,产生的主要原因是特征维度过少,拟合的模型不够复杂,无法满足训练样本,最终导致误差较大
- 通过增加更多的特征,来提升模型的复杂度,让它从欠拟合阶段往适度拟合阶段靠拢
- 过拟合问题产生的主要原因则是特征维度过多,导致拟合的模型过于完美地符合训练样本,但是无法适应测试样本或者新的数据
- 剪枝:删掉决策树中一些不是很重要的结点及对应的边,这其实就是在减少特征对模型的影响
- 随机森林:多次从全部样本中提取一定数量构建决策树,对于新的数据,每个决策树都会有自己的判断结果,我们取大多数决策树的意见作为最终结果